Data Struct
Minggu Pertama
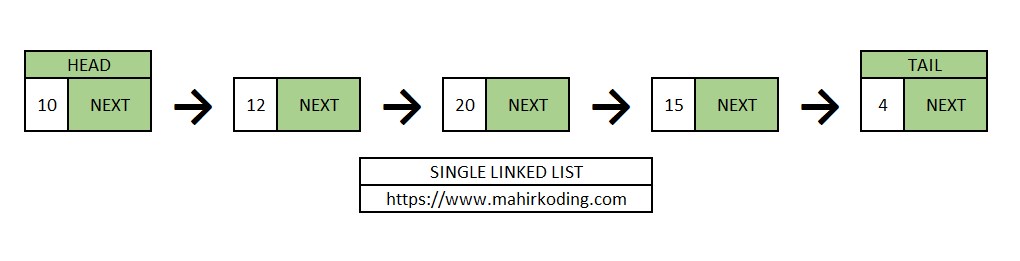
Linked List merupakan koleksi linear dari data, yang disebut sebagai nodes, dimana setiap node akan menunjuk pada node lain melalui sebuah pointer. Linked List dapat didefinisikan pula sebagai kumpulan nodes yang merepresentasikan sebuah sequence.
Representasi sebuah linked list dapat digambarkan melalui gambar di bawah ini:
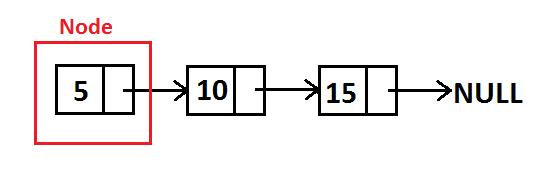
Sebuah linked list yang hanya memiliki 1 penghubung ke node lain disebut sebagai single linked list.
Di dalam sebuah linked list, ada 1 pointer yang menjadi gambaran besar, yakni pointer HEAD yang menunjuk pada node pertama di dalam linked list itu sendiri.
Sebuah linked list dikatakan kosong apabila isi pointer head adalah NULL.
Beberapa operasi yang biasanya ada di dalam sebuah linked list adalah:
- Push
Push merupakan sebuah operasi insert dimana di dalam linked list terdapat 2 kemungkinan insert, yaitu insert melalui depan (pushDepan) ataupun belakang (pushBelakang). Operasi pushDepan berarti data yang paling baru dimasukkan akan berada di depan data lainnya, dan sebaliknya pushBelakang berarti data yang paling baru akan berada di belakang data lainnya.
Representasinya adalah sebagai berikut:
- pushDepan: 5, 3, 7, 9 maka hasilnya adalah: 9 ->7 ->3 -> 5 -> NULL
- pushBelakang: 5, 3, 7, 9 maka hasilnya adalah: 5 ->3 ->7 ->9 -> NULL
- Pop
Pop, kebalikan dari push, merupakan operasi delete, dimana di dalam linked list memiliki 2 kemungkinan delete, yaitu melalui depan (popDepan) dan melalui belakang (popBelakang). PopDepan berarti data yang akan dihapus adalah data paling depan, dan popBelakang berarti data yang akan dihapus adalah data paling belakang (akhir).
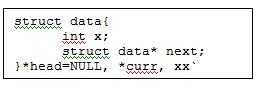
Dalam penerapan code single linked list, umumnya hanya digunakan pointer head sebagai pointer yang menunjuk pada linked list. Namun dalam pembahasan artikel ini akan digunakan 1 pointer tambahan, yakni TAIL untuk menunjuk data terakhir di dalam linked list dalam mempermudah proses pembahasan.
Dalam artikel ini, pembahasan code menggunakan Bahasa Pemrograman C dengan library malloc.h.
Apabila didefinisikan sebuah linked list sebagai berikut:
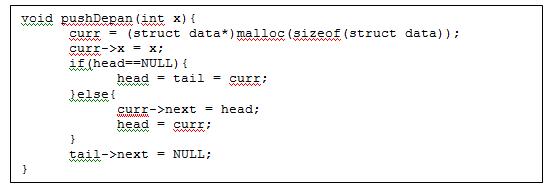
Operasi pushDepan dapat dilakukan dengan potongan code berikut ini.
Operasi pushBelakang dapat dilakukan dengan potongan code berikut ini.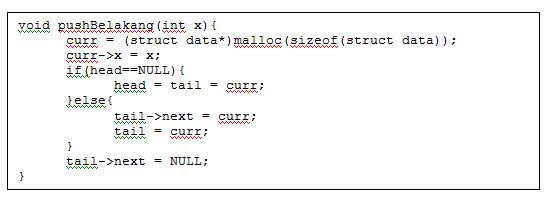
Operasi popDepan dapat dilakukan dengan potongan code berikut ini.

Operasi popBelakang dapat dilakukan dengan potongan code berikut ini.
Sedangkan untuk melihat data linked list, berikut ini adalah operasi yang biasanya digunakan:

Minggu Kedua
Single Linked List adalah salah satu bentuk implementasi dari struktur data yang paling sederhana. Seperti yang dijelaskan sebelumnya dalam konsep struktur data, single linked list bisa kita analogikan sebuah balok data dalam memory yang saling terhubung satu sama lain. Satu blok data dengan blok data lainnya dihubungkan melalui penanda berupa pointer (pointer bertugas menyimpan address blok data selanjutnya).
Dalam pembelajaran struktur data, kita akan lebih sering mengenal dengan istilah :
- Push untuk menambah data.
- PushHead – Menambah data ke barisan paling awal
- PushTail – Menambah data ke barisan paling akhir
- PushMid – Menambah data ke barisan di tengah (sorting)
- Pop untuk menghapus data.
- PopHead – Menghapus data paling awal
- PopTail – Menghapus data paling akhir
- PopMid – Menghapus data ditengah (sesuai parameter value)
Contoh pembuatan single linked list untuk menyimpan nama seseorang beserta umurnya.
Deklarasi Struct
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct human{
//menampung integer umur
int age;
//menampung nama manusia
char name[30];
//menampung alamat dari data selanjutnya
human *next;
}*head, *tail, *current;
//head adalah pointer yang menyimpan alamat data pertama
//tail adalah pointer yang menyimpan alamat data terakhir
//current adalah pointer yang digunakan sebagai temporary variabel
Push Head
void pushHead(int age, char name[]){
//alokasi memory untuk data baru
current = (human*)malloc(sizeof(struct human));
//assign data ke dalam struct
current->age = age;
strcpy(current->name, name);
//apabila linked list kosong/tidak ada data
if(head == NULL){
head = tail = current;
}
//kondisi tidak kosong
else{
current->next = head;
head = current;
}
}
Push Tail
void pushTail(int age, char name[]){
//alokasi memory untuk data baru
current = (human*)malloc(sizeof(struct human));
//assign data ke dalam struct
current->age = age;
strcpy(current->name, name);
//apabila linked list kosong/tidak ada data
if(head == NULL){
head = tail = current;
}
//kondisi tidak kosong
else{
tail->next = current;
tail = current;
}
tail->next = NULL;
}
Push Mid
void pushMid(int age, char name[]){
//alokasi memory untuk data baru
current = (human*)malloc(sizeof(struct human));
//assign data ke dalam struct
current->age = age;
strcpy(current->name, name);
//apabila linked list kosong/tidak ada data
if(head == NULL){
head = tail = current;
}
//jika umur data yang barusan dimasukkan lebih kecil dari umur data pertama (head)
else if(current->age < head->age){
pushHead(age, name);
}
//jika umur data yang barusan dimasukkan lebih besar dari umur data terakhir (tail)
else if(current->age > tail->age){
pushTail(age, name);
}
//push ditengah-tengah
else{
human *temp = head;
//mencari posisi data yang sesuai untuk diselipkan
while(temp->next->age < current->age){
temp = temp->next;
}
current->next = temp->next;
//mengarahkan penunjuk ke alamat data baru
temp->next = current;
}
}
Pop Head
void popHead(){
//inisialisasi current sebagai head
current=head;
//jika head kosong (tidak ada data)
if(head==NULL){
//cetak tidak ada data
printf("No data");
//jika head dan tail itu sama (hanya 1 data)
}else if(head==tail){
//head dan tail dikosongkan
head=tail=NULL;
//hapus data current (head)
free(current);
}else{
//set head menjadi data selanjutnya dari head
head=head->next;
//hapus data current (head)
free(current);
}
}
Pop Tail
void popTail(){
//jika head kosong (tidak ada data)
if(head==NULL){
//cetak tidak ada data
printf("No data");
//jika head dan tail itu sama (hanya 1 data)
}else if(head==tail){
//head dan tail dikosongkan
head=tail=NULL;
//hapus data current (head)
free(current);
}else{
//buat variabel penampung baru dan assign nilai mulai dari head
human *temp=head;
//looping untuk mencari posisi 1 data sebelum tail
while(temp->next!=tail){
//temp diubah menjadi 1 data selanjutnya
temp=temp->next;
}
//set data current menjadi tail
current=tail;
//set tail menjadi 1 data sebelum tail (hasil looping)
tail=temp;
//hapus data current (tail)
free(current);
//data setelah next dikosongkan/pointer next punya tail diberi NULL
tail->next=NULL;
}
}
Pop Mid
//kita akan menghapus data sesuai dengan umurnya.
void popMid(int age){
//jika head kosong (tidak ada data)
if(head==NULL){
printf("No data");
//jika umur si head(data pertama) sama dengan data umur yang mau dihapus
}else if(head->age==age){
//pop head
popHead();
//jika umur si tail(data terakhir) sama dengan data umur yang mau dihapus
}else if(tail->age==age){
//pop tail
popTail();
}else{
//buat variabel penampung baru dan assign nilai mulai dari head
human *temp=head;
//looping untuk mencari posisi 1 data sebelum tail
while(temp->next->age!=age && temp!=tail){
//temp diubah menjadi 1 data selanjutnya
temp=temp->next;
}
//set data current menjadi data selanjutnya dari temp
current=temp->next;
//data selanjutnya dari temp diubah menjadi 2 data setelah temp
temp->next=temp->next->next;
//hapus data current
free(current);
}
}
Pop Mid
void popAll(){
while(head!=NULL){
popHead();
}
}
Print Data
void print(){
current = head;
while(current != NULL){
printf("%s - %d\n",current->name,current->age);
current = current->next;
}
}
Main Function
int main(){
pushMid(18, "hery");
pushMid(17, "mahirkoding");
pushTail(22, "andi");
pushHead(15, "tono");
pushMid(11, "vandoro");
pushMid(23, "budi");
popHead();
popTail();
popMid(15);
//popAll();
print();
getchar();
return 0;
}
Hashing TablePengertian Hash TabelHash Table adalah sebuah struktur data yang terdiri atas sebuah tabel dan fungsi yang bertujuan untuk memetakan nilai kunci yang unik untuk setiap record (baris) menjadi angka (hash) lokasi record tersebut dalam sebuah tabel.Keunggulan dari struktur hash table ini adalah waktu aksesnya yang cukup cepat, jika record yang dicari langsung berada pada angka hash lokasi penyimpanannya. Akan tetapi pada kenyataannya sering sekali ditemukan hash table yang record-recordnya mempunyai angka hash yang sama (bertabrakan).Pemetaan hash function yang digunakan bukanlah pemetaan satusatu, (antara dua record yang tidak sama dapat dibangkitkan angka hash yang sama) maka dapat terjadi bentrokan (collision) dalam penempatan suatu data record. Untuk mengatasi hal ini, maka perlu diterapkan kebijakan resolusi bentrokan (collision resolution policy) untuk menentukan lokasi record dalam tabel. Umumnya kebijakan resolusi bentrokan adalah dengan mencari lokasi tabel yang masih kosong pada lokasi setelah lokasi yang berbentrokan.2. Operasi Pada Hash TabelØ insert: diberikan sebuah key dan nilai, insert nilai dalam tabelØ find: diberikan sebuah key, temukan nilai yang berhubungan dengan keyØ remove: diberikan sebuah key,temukan nilai yang berhubungan dengan key, kemudian hapus nilai tersebutØ getIterator: mengambalikan iterator,yang memeriksa nilai satu demi satu3. Struktur dan Fungsi pada Hash Tabel.Hash table menggunakan struktur data array asosiatif yang mengasosiasikan record dengan sebuah field kunci unik berupa bilangan (hash) yang merupakan representasi dari record tersebut. Misalnya, terdapat data berupa string yang hendak disimpan dalam sebuah hash table. String tersebut direpresentasikan dalam sebuah field kunci k.Cara untuk mendapatkan field kunci ini sangatlah beragam, namun hasil akhirnya adalah sebuah bilangan hash yang digunakan untuk menentukan lokasi record. Bilangan hash ini dimasukan ke dalam hash function dan menghasilkan indeks lokasi record dalam tabel.k(x) = fungsi pembangkit field kunci (1)h(x) = hash function (2)Contohnya, terdapat data berupa string “abc” dan “xyz” yang hendak disimpan dalam struktur hash table. Lokasi dari record pada tabel dapat
dihitung dengan menggunakan h(k(“abc”)) dan h(k(“xyz”)).
berikutnya secara incremental.
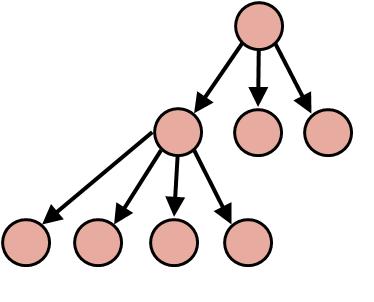
http://sourcecodemania.com/wp-content/uploads/2012/05/tree-general.jpgLalu, ada lagi yang namanya Binary Tree. Apa bedanya? Sebenarnya sama sama konsepnya dengan Tree. Hanya saja, kita akan mengambil sifat bilangan biner yang selalu bernilai 1 atau 0 (2 pilihan). Berarti, binary tree adalah tree yang hanya dapat mempunyai maksimal 2 percabangan saja. Untuk lebih jelasnya, lihat gambar di bawah ini.
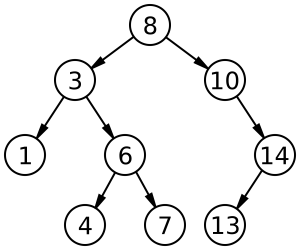
https://www.cs.cmu.edu/~adamchik/15-121/lectures/Trees/pix/binaryTree.bmpLanjut lagi, sekarang kita akan memasuki pembelajaran intinya yaitu Binary Search Tree atau sering disingkat BST. Apalagi BST itu? Dan apa bedanya dengan yang dua diatas? Sebenarnya mirip-mirip saja, Binary Search Tree adalah struktur data yang mengadopsi konsep Binary Tree namun terdapat aturan bahwa setiap clild node sebelah kiri selalu lebih kecil nilainya dari pada root node. Begitu pula sebaliknya, setiap child node sebelah kanan selalu lebih besar nilainya daripada root node.
https://upload.wikimedia.org/wikipedia/commons/thumb/d/da/Binary_search_tree.svg/2000px-Binary_search_tree.svg.pngKenapa harus membedakan kiri dan kanan sesuai besaran nilainya? Tujuannya untuk memberikan efisiensi terhadap proses searching. Kalau struktur data tree sudah tersusun rapi sesuai aturan mainnya, proses search akan lebih cepat.Aturan main Binary Search Tree :
- Setiap child node sebelah kiri harus lebih kecil nilainya daripada root nodenya.
- Setiap child node sebelah kanan harus lebih besar nilainya daripada root nodenya.
Lalu, ada 3 jenis cara untuk melakukan penelusuran data (traversal) pada BST :
- PreOrder : Print data, telusur ke kiri, telusur ke kanan
- InOrder : Telusur ke kiri, print data, telusur ke kanan
- Post Order : Telusur ke kiri, telusur ke kanan, print data
Berikut adalah contoh implementasi Binary Search Tree pada C beserta searching datanya :#include <stdio.h> #include <stdlib.h> //inisialisasi struct struct data{ int number; //pointer untuk menampung percabangan kiri dan kanan data *left, *right; }*root; //fungsi push untuk menambah data void push(data **current, int number){ //jika pointer current kosong maka akan membuat blok data baru if((*current)==NULL){ (*current) = (struct data *)malloc(sizeof data); //mengisi data (*current)->number=number; (*current)->left = (*current)->right = NULL; //jika tidak kosong, maka akan dibandingkan apakah angka yang //ingin dimasukkan lebih kecil dari pada root //kalau iya, maka belok ke kiri dan lakukan rekursif //terus menerus hingga kosong }else if(number < (*current)->number){ push(&(*current)->left, number); //jika lebih besar, belok ke kanan }else if(number >= (*current)->number){ push(&(*current)->right, number); } } //preOrder : cetak, kiri, kanan void preOrder(data **current){ if((*current)!=NULL){ printf("%d -> ", (*current)->number); preOrder(&(*current)->left); preOrder(&(*current)->right); } } //inOrder : kiri, cetak, kanan void inOrder(data **current){ if((*current)!=NULL){ inOrder(&(*current)->left); printf("%d -> ", (*current)->number); inOrder(&(*current)->right); } } //postOrder : kiri, kanan, cetak void postOrder(data **current){ if((*current)!=NULL){ postOrder(&(*current)->left); postOrder(&(*current)->right); printf("%d -> ", (*current)->number); } } //searching data void search(data **current, int number){ //jika pointer current memiliki data if((*current)!=NULL){ //cek, apakah datanya lebih kecil. Jika iya, belok ke kiri if(number<(*current)->number){ search(&(*current)->left,number); //jika lebih besar, maka belok ke kanan }else if(number>(*current)->number){ search(&(*current)->right,number); //jika sama dengan, maka angka ketemu }else{ printf("Found : %d", (*current)->number); } //jika tidak ada data lagi (not found) }else{ printf("Not Found."); } } void main(){ push(&root, 11); push(&root, 22); push(&root, 13); push(&root, 15); push(&root, 9); inOrder(&root); printf("\n"); preOrder(&root); printf("\n"); postOrder(&root); printf("\n"); search(&root,91); getchar(); }
No comments:
Post a Comment