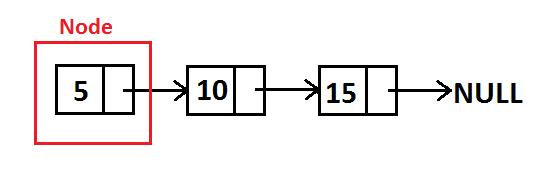
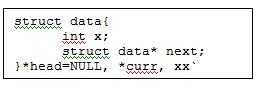
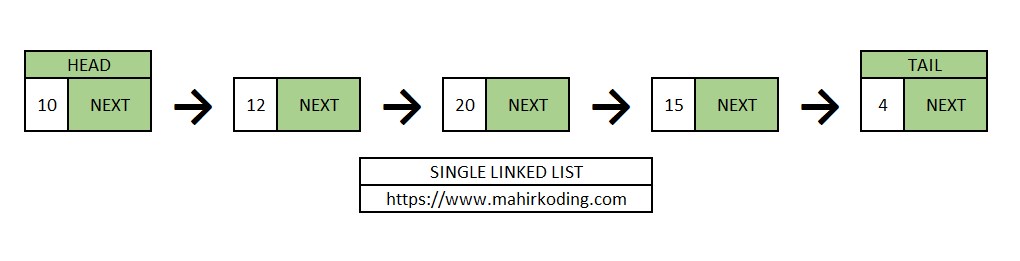
Dalam penerapan code single linked list, umumnya hanya digunakan pointer head sebagai pointer yang menunjuk pada linked list. Namun dalam pembahasan artikel ini akan digunakan 1 pointer tambahan, yakni TAIL untuk menunjuk data terakhir di dalam linked list dalam mempermudah proses pembahasan.
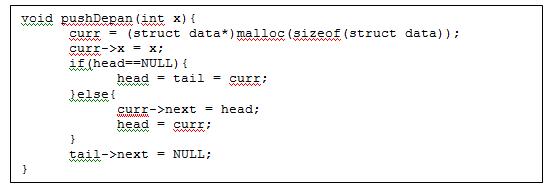
Operasi pushDepan dapat dilakukan dengan potongan code berikut ini.
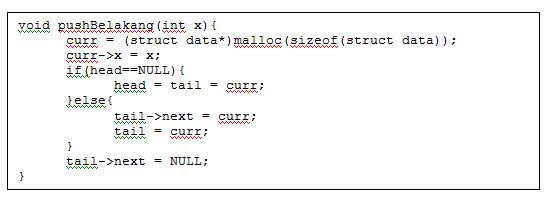
Operasi popDepan dapat dilakukan dengan potongan code berikut ini.
Minggu Kedua
Single Linked List adalah salah satu bentuk implementasi dari struktur data yang paling sederhana. Seperti yang dijelaskan sebelumnya dalam konsep struktur data, single linked list bisa kita analogikan sebuah balok data dalam memory yang saling terhubung satu sama lain. Satu blok data dengan blok data lainnya dihubungkan melalui penanda berupa pointer (pointer bertugas menyimpan address blok data selanjutnya).
Dalam pembelajaran struktur data, kita akan lebih sering mengenal dengan istilah :
- Push untuk menambah data.
- PushHead – Menambah data ke barisan paling awal
- PushTail – Menambah data ke barisan paling akhir
- PushMid – Menambah data ke barisan di tengah (sorting)
- Pop untuk menghapus data.
- PopHead – Menghapus data paling awal
- PopTail – Menghapus data paling akhir
- PopMid – Menghapus data ditengah (sesuai parameter value)
Contoh pembuatan single linked list untuk menyimpan nama seseorang beserta umurnya.
Deklarasi Struct
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct human{
//menampung integer umur
int age;
//menampung nama manusia
char name[30];
//menampung alamat dari data selanjutnya
human *next;
}*head, *tail, *current;
//head adalah pointer yang menyimpan alamat data pertama
//tail adalah pointer yang menyimpan alamat data terakhir
//current adalah pointer yang digunakan sebagai temporary variabel
Push Head
void pushHead(int age, char name[]){
//alokasi memory untuk data baru
current = (human*)malloc(sizeof(struct human));
//assign data ke dalam struct
current->age = age;
strcpy(current->name, name);
//apabila linked list kosong/tidak ada data
if(head == NULL){
head = tail = current;
}
//kondisi tidak kosong
else{
current->next = head;
head = current;
}
}
Push Tail
void pushTail(int age, char name[]){
//alokasi memory untuk data baru
current = (human*)malloc(sizeof(struct human));
//assign data ke dalam struct
current->age = age;
strcpy(current->name, name);
//apabila linked list kosong/tidak ada data
if(head == NULL){
head = tail = current;
}
//kondisi tidak kosong
else{
tail->next = current;
tail = current;
}
tail->next = NULL;
}
Push Mid
void pushMid(int age, char name[]){
//alokasi memory untuk data baru
current = (human*)malloc(sizeof(struct human));
//assign data ke dalam struct
current->age = age;
strcpy(current->name, name);
//apabila linked list kosong/tidak ada data
if(head == NULL){
head = tail = current;
}
//jika umur data yang barusan dimasukkan lebih kecil dari umur data pertama (head)
else if(current->age < head->age){
pushHead(age, name);
}
//jika umur data yang barusan dimasukkan lebih besar dari umur data terakhir (tail)
else if(current->age > tail->age){
pushTail(age, name);
}
//push ditengah-tengah
else{
human *temp = head;
//mencari posisi data yang sesuai untuk diselipkan
while(temp->next->age < current->age){
temp = temp->next;
}
current->next = temp->next;
//mengarahkan penunjuk ke alamat data baru
temp->next = current;
}
}
Pop Head
void popHead(){
//inisialisasi current sebagai head
current=head;
//jika head kosong (tidak ada data)
if(head==NULL){
//cetak tidak ada data
printf("No data");
//jika head dan tail itu sama (hanya 1 data)
}else if(head==tail){
//head dan tail dikosongkan
head=tail=NULL;
//hapus data current (head)
free(current);
}else{
//set head menjadi data selanjutnya dari head
head=head->next;
//hapus data current (head)
free(current);
}
}
Pop Tail
void popTail(){
//jika head kosong (tidak ada data)
if(head==NULL){
//cetak tidak ada data
printf("No data");
//jika head dan tail itu sama (hanya 1 data)
}else if(head==tail){
//head dan tail dikosongkan
head=tail=NULL;
//hapus data current (head)
free(current);
}else{
//buat variabel penampung baru dan assign nilai mulai dari head
human *temp=head;
//looping untuk mencari posisi 1 data sebelum tail
while(temp->next!=tail){
//temp diubah menjadi 1 data selanjutnya
temp=temp->next;
}
//set data current menjadi tail
current=tail;
//set tail menjadi 1 data sebelum tail (hasil looping)
tail=temp;
//hapus data current (tail)
free(current);
//data setelah next dikosongkan/pointer next punya tail diberi NULL
tail->next=NULL;
}
}
Pop Mid
//kita akan menghapus data sesuai dengan umurnya.
void popMid(int age){
//jika head kosong (tidak ada data)
if(head==NULL){
printf("No data");
//jika umur si head(data pertama) sama dengan data umur yang mau dihapus
}else if(head->age==age){
//pop head
popHead();
//jika umur si tail(data terakhir) sama dengan data umur yang mau dihapus
}else if(tail->age==age){
//pop tail
popTail();
}else{
//buat variabel penampung baru dan assign nilai mulai dari head
human *temp=head;
//looping untuk mencari posisi 1 data sebelum tail
while(temp->next->age!=age && temp!=tail){
//temp diubah menjadi 1 data selanjutnya
temp=temp->next;
}
//set data current menjadi data selanjutnya dari temp
current=temp->next;
//data selanjutnya dari temp diubah menjadi 2 data setelah temp
temp->next=temp->next->next;
//hapus data current
free(current);
}
}
Pop Mid
void popAll(){
while(head!=NULL){
popHead();
}
}
Print Data
void print(){
current = head;
while(current != NULL){
printf("%s - %d\n",current->name,current->age);
current = current->next;
}
}
Main Function
int main(){
pushMid(18, "hery");
pushMid(17, "mahirkoding");
pushTail(22, "andi");
pushHead(15, "tono");
pushMid(11, "vandoro");
pushMid(23, "budi");
popHead();
popTail();
popMid(15);
//popAll();
print();
getchar();
return 0;
}
Hashing Table
Pengertian Hash Tabel
Hash Table adalah sebuah struktur data yang terdiri atas sebuah tabel dan fungsi yang bertujuan untuk memetakan nilai kunci yang unik untuk setiap record (baris) menjadi angka (hash) lokasi record tersebut dalam sebuah tabel.
Keunggulan dari struktur hash table ini adalah waktu aksesnya yang cukup cepat, jika record yang dicari langsung berada pada angka hash lokasi penyimpanannya. Akan tetapi pada kenyataannya sering sekali ditemukan hash table yang record-recordnya mempunyai angka hash yang sama (bertabrakan).
Pemetaan hash function yang digunakan bukanlah pemetaan satusatu, (antara dua record yang tidak sama dapat dibangkitkan angka hash yang sama) maka dapat terjadi bentrokan (collision) dalam penempatan suatu data record. Untuk mengatasi hal ini, maka perlu diterapkan kebijakan resolusi bentrokan (collision resolution policy) untuk menentukan lokasi record dalam tabel. Umumnya kebijakan resolusi bentrokan adalah dengan mencari lokasi tabel yang masih kosong pada lokasi setelah lokasi yang berbentrokan.
2. Operasi Pada Hash Tabel
Ø insert: diberikan sebuah key dan nilai, insert nilai dalam tabel
Ø find: diberikan sebuah key, temukan nilai yang berhubungan dengan key
Ø remove: diberikan sebuah key,temukan nilai yang berhubungan dengan key, kemudian hapus nilai tersebut
Ø getIterator: mengambalikan iterator,yang memeriksa nilai satu demi satu
3. Struktur dan Fungsi pada Hash Tabel.
Hash table menggunakan struktur data array asosiatif yang mengasosiasikan record dengan sebuah field kunci unik berupa bilangan (hash) yang merupakan representasi dari record tersebut. Misalnya, terdapat data berupa string yang hendak disimpan dalam sebuah hash table. String tersebut direpresentasikan dalam sebuah field kunci k.
Cara untuk mendapatkan field kunci ini sangatlah beragam, namun hasil akhirnya adalah sebuah bilangan hash yang digunakan untuk menentukan lokasi record. Bilangan hash ini dimasukan ke dalam hash function dan menghasilkan indeks lokasi record dalam tabel.
k(x) = fungsi pembangkit field kunci (1)
h(x) = hash function (2)
Contohnya, terdapat data berupa string “abc” dan “xyz” yang hendak disimpan dalam struktur hash table. Lokasi dari record pada tabel dapat
dihitung dengan menggunakan h(k(“abc”)) dan h(k(“xyz”)).
Gambar 1. Penempatan record pada hash table
Jika hasil dari hash function menunjuk ke lokasi memori yang sudah terisi oleh sebuah record maka dibutuhkan kebijakan resolusi bentrokan. Biasanya masalah ini diselesaikan dengan mencari lokasi record kosong
berikutnya secara incremental.
Gambar 2. Resolusi bentrokan pada hash table
Deklarasi utama hash tabel adalah dengan struct, yaitu:
typedef struct hashtbl {
hash_size size;
struct hashnode_s **nodes;
hash_size (*hashfunc)(const char *);
} HASHTBL;
Anggota simpul pada hashtbl mempersiapkan penunjuk kepada unsur pertama yang terhubung dengan daftar. unsur ini direpresentasikan oleh struct hashnode_:
struct hashnode_s {
char *key;
void *data;
struct hashnode_s *next;
};
Inisialisasi
Deklarasi untuk inisialisasi hash tabel seperti berikut:
HASHTBL *hashtbl_create(hash_size size, hash_size
(*hashfunc)(const char *))
{
HASHTBL *hashtbl;
if(!(hashtbl=malloc(sizeof(HASHTBL)))) return NULL;
free(hashtbl);
return NULL;
}
hashtbl->size=size;
if(hashfunc) hashtbl->hashfunc=hashfunc;
else hashtbl->hashfunc=def_hashfunc;
return hashtbl;
}
Cleanup
Hash Tabel dapat menggunakan fungsi linked lists untuk menghapus element
atau daftar anggota dari hash tabel .
Deklarasinya:
void hashtbl_destroy(HASHTBL *hashtbl)
{
hash_size n;
struct hashnode_s *node, *oldnode;
for(n=0; n<hashtbl->size; ++n) {
node=hashtbl->nodes[n];
while(node) {
free(node->key);
oldnode=node;
node=node->next;
free(oldnode);
}
}
free(hashtbl->nodes);
free(hashtbl);
}
Menambah Elemen Baru
Untuk menambah elemen baru maka harus menentukan ukuran pada hash tabel. Dengan deklarasi sebagai berikut:
int hashtbl_insert(HASHTBL *hashtbl, const char *key, void
*data)
{
struct hashnode_s *node;
hash_size hash=hashtbl->hashfunc(key)%hashtbl->size;
Penambahan elemen baru dengan teknik pencarian menggunakan linked lists
untuk mengetahui ada tidaknya data dengan key yang sama yang
sebelumnya sudah dimasukkan, menggunakan deklarasi berikut:
node=hashtbl->nodes[hash];
while(node) {
if(!strcmp(node->key, key)) {
node->data=data;
return 0;
}
node=node->next;
}
Jika tidak menemukan key yang sama, maka pemasukan elemen baru pada
linked lists dengan deklarasi berikut:
if(!(node=malloc(sizeof(struct hashnode_s)))) return -1;
if(!(node->key=mystrdup(key))) {
free(node);
return -1;
}
node->data=data;
node->next=hashtbl->nodes[hash];
hashtbl->nodes[hash]=node;
return 0;
}
Menghapus sebuah elemen
Untuk menghapus sebuah elemen dari hash tabel yaitu dengan mencari nilai hash menggunakan deklarasi linked list dan menghapusnya jika nilai tersebut ditemukan. Deklarasinya sebagai berikut:
int hashtbl_remove(HASHTBL *hashtbl, const char *key)
{
struct hashnode_s *node, *prevnode=NULL;
hash_size hash=hashtbl->hashfunc(key)%hashtbl->size;
node=hashtbl->nodes[hash];
while(node) {
if(!strcmp(node->key, key)) {
free(node->key);
if(prevnode) prevnode->next=node->next;
else hashtbl->nodes[hash]=node->next;
free(node);
return 0;
}
prevnode=node;
node=node->next;
}
return -1;
}
Searching
Teknik pencarian pada hash tabel yaitu dengan mencari nilai hash yang sesuai menggunakan deklarasi sama seperti pada linked list. Jika data tidak
ditemukan maka menggunakan nilai balik NULL. Deklarasinya sebagai berikut:
void *hashtbl_get(HASHTBL *hashtbl, const char *key)
{
struct hashnode_s *node;
hash_size hash=hashtbl->hashfunc(key)%hashtbl->size;
node=hashtbl->nodes[hash];
while(node) {
if(!strcmp(node->key, key)) return node->data;
node=node->next;
}
return NULL;
}
Resizing
Jumlah elemen pada hash tabel tidak selalu diketahui ketika terjadi penambahan data. Jika jumlah elemen bertambah begitu besar maka itu akan mengurangi operasi pada hash tabel yang dapat menyebabkan terjadinya kegagalan memory. Fungsi Resizing hash tabel digunakan untuk mencegah terjadinya hal itu.Dekalarsinya sebagai berikut:
int hashtbl_resize(HASHTBL *hashtbl, hash_size size)
{
HASHTBL newtbl;
hash_size n;
struct hashnode_s *node,*next;
newtbl.size=size;
newtbl.hashfunc=hashtbl->hashfunc;
if(!(newtbl.nodes=calloc(size, sizeof(struct
hashnode_s*)))) return -1;
for(n=0; n<hashtbl->size; ++n) {
for(node=hashtbl->nodes[n]; node; node=next) {
next = node->next;
hashtbl_insert(&newtbl, node->key,
node->data);
hashtbl_remove(hashtbl, node->key);
}
}
free(hashtbl->nodes);
hashtbl->size=newtbl.size;
hashtbl->nodes=newtbl.nodes;
return 0;
}
Lookup pada Hash table
Salah satu keunggulan struktur hash table dibandingkan dengan struktur tabel biasa adalah kecepatannya dalam mencari data. Terminologi lookup mengacu pada proses yang bertujuan untuk mencari sebuah record pada sebuah tabel, dalam hal ini adalah hash table.
Dengan menggunakan hash function, sebuah lokasi dari record yang dicari
bisa diperkirakan. Jika lokasi yang tersebut berisi record yang dicari, maka
pencarian berhasil. Inilah kasus terbaik dari pencarian pada hash table. Namun, jika record yang hendak dicari tidak ditemukan di lokasi yang diperkirakan, maka akan dicari lokasi berikutnya sesuai dengan kebijakan resolusi bentrokan. Pencarian akan berhenti jika record ditemukan, pencarian bertemu dengan tabel kosong, atau pencarian telah kembali ke lokasi semula.
Collision (Tabrakan)
Keterbatasan tabel hash menyebabkan ada dua angka yang jika dimasukkan ke dalam fungsi hash maka menghasilkan nilai yang sama. Hal ini disebut dengan collision.
contoh: Kita ingin memasukkan angka 6 dan 29.
Hash(6) = 6 % 23 = 6
Hash(29)= 29 % 23 = 6
Pertama-tama anggap tabel masih kosong. Pada saat angka 6 masuk akan ditempatkan pada posisi indeks 6, angka kedua 29 seharusnya ditempatkan di indeks 6 juga, namun karena indeks ke-6 sudah ditempati maka 29 tidak bisa ditempatkan di situ, di sinilah terjadi collision. Cara penanganannya bermacam-macam :
Collision Resolution Open Addressing
1. Linear Probing
Pada saat terjadi collision, maka akan mencari posisi yang kosong di bawah tempat terjadinya collision, jika masih penuh terus ke bawah, hingga ketemu tempat yang kosong. Jika tidak ada tempat yang kosong berarti HashTable sudah penuh. Contoh deklarasi program:
struct { ... } node;
node Table[M]; int Free;
/* insert K */
addr = Hash(K);
if (IsEmpty(addr)) Insert(K,addr);
else {
/* see if already stored */
test:
if (Table[addr].key == K) return;
else {
addr = Table[addr].link; goto test;}
/* find free cell */
Free = addr;
do { Free--; if (Free<0) Free=M-1; }
while (!IsEmpty(Free) && Free!=addr)
if (!IsEmpty(Free)) abort;
else {
Insert(K,Free); Table[addr].link = Free;}
}
2. Quadratic Probing
Penanganannya hampir sama dengan metode linear, hanya lompatannya tidak satu-satu, tetapi quadratic ( 12, 22, 32, 42, … )
3. Double Hashing
Pada saat terjadi collision, terdapat fungsi hash yang kedua untuk menentukan posisinya kembali.
Collision Resolution Chaining
Ø Tambahkan key and entry di manapun dalam list (lebih mudah dari depan)
Ø Kerugian:
- Overhead pada memory tinggi jika jumlah entry sedikit
Ø Keunggulan dibandingkan open addressing:
- Proses insert dan remove lebih sederhana
- Ukuran Array bukan batasan (tetapi harus tetap meminimalisir
collision: buat ukuran tabel sesuai dengan jumlah key dan entry yang diharapkan)
Binary Tree
Sebelum mengenal lebih jauh tentang Binary Search Tree, ada baiknya kita membahas struktur data Tree terlebih dahulu. Tree (pohon) adalah salah satu bentuk struktur data yang menggambarkan hubungan hierarki antar elemen-elemennya (seperti relasi one to many). Sebuah node dalam tree biasanya bisa memiliki beberapa node lagi sebagai percabangan atas dirinya.
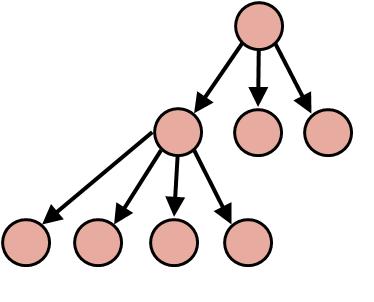
http://sourcecodemania.com/wp-content/uploads/2012/05/tree-general.jpg
Lalu, ada lagi yang namanya Binary Tree. Apa bedanya? Sebenarnya sama sama konsepnya dengan Tree. Hanya saja, kita akan mengambil sifat bilangan biner yang selalu bernilai 1 atau 0 (2 pilihan). Berarti, binary tree adalah tree yang hanya dapat mempunyai maksimal 2 percabangan saja. Untuk lebih jelasnya, lihat gambar di bawah ini.
https://www.cs.cmu.edu/~adamchik/15-121/lectures/Trees/pix/binaryTree.bmp
Lanjut lagi, sekarang kita akan memasuki pembelajaran intinya yaitu Binary Search Tree atau sering disingkat BST. Apalagi BST itu? Dan apa bedanya dengan yang dua diatas? Sebenarnya mirip-mirip saja, Binary Search Tree adalah struktur data yang mengadopsi konsep Binary Tree namun terdapat aturan bahwa setiap clild node sebelah kiri selalu lebih kecil nilainya dari pada root node. Begitu pula sebaliknya, setiap child node sebelah kanan selalu lebih besar nilainya daripada root node.
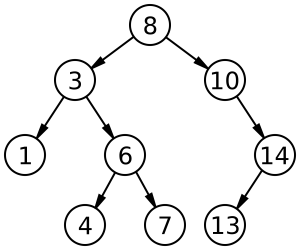
https://upload.wikimedia.org/wikipedia/commons/thumb/d/da/Binary_search_tree.svg/2000px-Binary_search_tree.svg.png
Kenapa harus membedakan kiri dan kanan sesuai besaran nilainya? Tujuannya untuk memberikan efisiensi terhadap proses searching. Kalau struktur data tree sudah tersusun rapi sesuai aturan mainnya, proses search akan lebih cepat.
Aturan main Binary Search Tree :
- Setiap child node sebelah kiri harus lebih kecil nilainya daripada root nodenya.
- Setiap child node sebelah kanan harus lebih besar nilainya daripada root nodenya.
Lalu, ada 3 jenis cara untuk melakukan penelusuran data (traversal) pada BST :
- PreOrder : Print data, telusur ke kiri, telusur ke kanan
- InOrder : Telusur ke kiri, print data, telusur ke kanan
- Post Order : Telusur ke kiri, telusur ke kanan, print data
Berikut adalah contoh implementasi Binary Search Tree pada C beserta searching datanya :
#include <stdio.h>
#include <stdlib.h>
//inisialisasi struct
struct data{
int number;
//pointer untuk menampung percabangan kiri dan kanan
data *left, *right;
}*root;
//fungsi push untuk menambah data
void push(data **current, int number){
//jika pointer current kosong maka akan membuat blok data baru
if((*current)==NULL){
(*current) = (struct data *)malloc(sizeof data);
//mengisi data
(*current)->number=number;
(*current)->left = (*current)->right = NULL;
//jika tidak kosong, maka akan dibandingkan apakah angka yang
//ingin dimasukkan lebih kecil dari pada root
//kalau iya, maka belok ke kiri dan lakukan rekursif
//terus menerus hingga kosong
}else if(number < (*current)->number){
push(&(*current)->left, number);
//jika lebih besar, belok ke kanan
}else if(number >= (*current)->number){
push(&(*current)->right, number);
}
}
//preOrder : cetak, kiri, kanan
void preOrder(data **current){
if((*current)!=NULL){
printf("%d -> ", (*current)->number);
preOrder(&(*current)->left);
preOrder(&(*current)->right);
}
}
//inOrder : kiri, cetak, kanan
void inOrder(data **current){
if((*current)!=NULL){
inOrder(&(*current)->left);
printf("%d -> ", (*current)->number);
inOrder(&(*current)->right);
}
}
//postOrder : kiri, kanan, cetak
void postOrder(data **current){
if((*current)!=NULL){
postOrder(&(*current)->left);
postOrder(&(*current)->right);
printf("%d -> ", (*current)->number);
}
}
//searching data
void search(data **current, int number){
//jika pointer current memiliki data
if((*current)!=NULL){
//cek, apakah datanya lebih kecil. Jika iya, belok ke kiri
if(number<(*current)->number){
search(&(*current)->left,number);
//jika lebih besar, maka belok ke kanan
}else if(number>(*current)->number){
search(&(*current)->right,number);
//jika sama dengan, maka angka ketemu
}else{
printf("Found : %d", (*current)->number);
}
//jika tidak ada data lagi (not found)
}else{
printf("Not Found.");
}
}
void main(){
push(&root, 11);
push(&root, 22);
push(&root, 13);
push(&root, 15);
push(&root, 9);
inOrder(&root);
printf("\n");
preOrder(&root);
printf("\n");
postOrder(&root);
printf("\n");
search(&root,91);
getchar();
}
https://www.mahirkoding.com/struktur-data-binary-search-tree-bst/
Balanced Binary Search Tree
Dalam Binary Search Tree, tinggi maksimal suatu tree adalah N-1, dimana N adalah jumlah node. Dalam melakukan suatu operasi, misalnya insertion, deletion, dan seaching, kecepatan waktu merupakan hal yang cukup penting untuk diperhatikan. Setiap operasi pasti di harapkan dapat berjalan dengan cepat, sehingga semakin cepat suatu operasi maka semakin baik. Cepat atau tidaknya suatu operasi, bergantung pada ketinggian tree tersebut, semakin rendah tingginya, maka semakin cepat.
Dengan Balanced Binary Search Tree, kita dapat membuat suatu tree dengan tinggi minimum.
untuk menetapkan tingginya, kita dapat menggunakan rumus berikut:
O(log n)
2 contoh tree yang termasuk ke dalam balanced binary search tree, yaitu :
- AVL Tree
- Red Black Tree (RBT)
AVL Tree
AVL adalah balanced binary search tree dimana ia memiliki perbedaan jumlah node pada subtree kiri dan subtree kanannya maksimal 1 (atau dapat dikatakan antara tingginya sama atau selisih satu).
Berikut gambarannya :
 |
| AVL Tree, karena factor tertingginya 1 |
 |
| Not AVL Tree, karena balance factor tertingginya 2, sedangkan syarat AVL adalah selisihnya maksimal 1 |
Note :
Cara menentukan Height dan Balance Factor :
Height :
- Jika node (root) tidak memiliki subtree heightnya = 0
- Jika node adalah leaf, height = 1
- Jika internal node, maka height = height tertinggi dari anak + 1
Balance Factor :
-selisih height antara anak kiri dan kanan, jika tidak memiliki anak, dianggap 0.
AVL Tree Operations : Insertion
Insert suatu node pada AVL sama halnya pada insert node pada binary search tree, dimana node baru diposisikan sebagai leaf. Setelah memasukkan node baru, maka harus dilakukan penyeimbangan kembali pada path dari node yang baru di insert atau path terdalam. Namun biasanya, path terdalam adalah path dari node yang baru saja di insert.
Ada 4 kasus yang biasanya terjadi saat operasi insert dilakukan, yaitu :
anggap T adalah node yang harus diseimbangkan kembali
- Kasus 1 : node terdalam terletak pada subtree kiri dari anak kiri T (left-left)
- Kasus 2 : node terdalam terletak pada subtree kanan dari anak kanan T (right-right)
- Kasus 3 : node terdalam terletak pada subtree kanan dari anak kiri T (right-left)
- Kasus 4 : node terdalam terletak pada subtree kiri dari anak kanan T (left-right)
Ke-4 kasus tersebut dapat diselesaikan dengan melakukan rotasi
- Kasus 1 dan 2 dengan single rotation
- Kasus 3 dan 4 dengan double rotation
Single Rotation
Single rotasi (rotasi 1x) dilakukan apabila searah, left-left atau right-right
Gambaran Single Rotation :
 |
| Single Rotation
pada contoh diatas, left-left karena dari 30 ke 22 ke kiri, dan dari 22 ke 15 ke kiri juga |
Double Rotation
Double rotasi (rotasi 2x) dilakukan apabila searah, left-right atau right-left.
Gambaran Double Rotation :
 |
| Step 1 (Rotasi pertama)
kasus diatas adalah left-right |
Step 2 (Rotasi kedua)
kasus diatas, left-left
AVL Tree Operations : Deletion
Operasi penghapusan node sama seperti pada Binary Search Tree, yaitu node yang dihapus digantikan oleh node terbesar pada subtree kiri atau node terkecil pada subtree kanan. Jika yang dihapus adalah leaf, maka langsung hapus saja. Namun jika node yang dihapus memiliki child maka childnya yang menggantikannya. Namun setelah operasi penghapusan dilakukan, cek kembali apakah tree sudah seimbang atau belum, jika belum maka harus diseimbangkan kembali. Cara menyeimbangkannya pun sama seperti insertion.
 |
| delete node 60 |
 |
| node 55 tidak seimbang, karena anak kiri 0 dan anak kanan 2, selisih 2.
diseimbangkan dengan single rotation (left-left) karena 55 ke 65 kiri dan 65 ke 70 kiri
akan tetapi, node 50 menjadi tidak seimbang, di subtree kiri 4 dan subtree kanan 2 |
 |
| diseimbangkan dengan double rotation (left-right) karena dari 50 ke 25 kiri dan 25 ke 40 kanan |
 |
| AVL yang sudah balance |
Red Black Tree (RBT)
Suatu tree dikatakan RBT apabila :
- setiap node memiliki warna (hitam atau merah)
- root berwarna hitam
- eksternal node berwarna hitam
- node merah tidak memiliki anak merah
- setiap path memiliki jumlah node hitam yang sama dengan path lainnya
berikut contoh RBT :
RBT operations : Insertion
aturan insertion :
- node baru berwarna merah
- node merah tidak boleh memiliki anak merah
apa yang dilakukan jika node merah memiliki node child merah?
cek uncle/paman dari node merah (anak)
- jika uncle berwarna merah, maka ubah warna parent dan uncle menjadi hitam, dan grand parent menjadi merah.
- jika uncle berwarna hitam, lakukan rotasi single/double, kemudian setelah rotasi, parent berwarna hitam, anak berwarna merah
- jika tidak memiliki paman, maka defaulnya adalah hitam (dilihat dari external nodenya). sehingga mengikuti aturan kedua (uncle hitam)
contoh 1 :
 |
| insert node x, parent-y- merah memiliki child -x- merah, maka melanggar aturan.
lihat unclenya, -d- berwarna merah, maka mengikuti aturan pertama
y dan d menjadi hitam, kemudian z sbg grand parent berwarna merah |
 |
| insert node x, parent-y- merah memiliki child -x- merah, maka melanggar aturan.
lihat unclenya, karena tidak memiliki uncle maka ikuti aturan ketiga
rotasi yang dilakukan pun sama seperti AVL. pada kasus diatas dilakukan single rotation |
contoh 3 :
 |
| insert node y, parent-x- merah memiliki child -y- merah, maka melanggar aturan.
lihat unclenya, karena tidak memiliki uncle maka ikuti aturan ketiga
rotasi yang dilakukan pun sama seperti AVL. pada kasus diatas dilakukan double rotation |
|
RBT operations : Deletion
Deletion RBT sama seperti deletion pada AVL
aturannya :
anggap M = node yang di delete dan C = node yang menggantikan
- jika M merah, diganti dengan C yang berwarna hitam
- jika M hitam dan C merah, maka M diganti C dan C berubah warna menjadi hitam
- jika M hitam dan C hitam, kita lakukan pemisalan kembali :
C = N,
P = parent N,
S = sibling N,
Sl = anak kiri S,
Sr = anak kanan S
kita perhatikan siblingnya :
a. jika S merah, ubah warna N dan P (tukar warna), kemudian rotate di P
b. jika S hitam dan Sl, Sr hitam, maka ubah S menjadi merah
c. jika S hitam dan Sl atau Sr ada yang merah maka lakukan rotasi single/double
contoh 1 :
 |
| kita akan menghapus node 3 |
 |
| karena node 3 adalah leaf dan berwarna merah, maka langsung hapus saja. tapi jika 5 merah dan kedua anaknnya 3 dan 6 hitam, maka ketika node 3 dihapus, 5 dan 6 bertukar warna menjadi 5 merah dan 6 hitam |
contoh 2 :
 |
| pada kali ini kita akan menghapus node 8, karena node 8 memiliki anak, maka yang menggantikannya adalah anaknya, pada kali ini kita mengambil anak kanan terkecil, yaitu 9. pada penghapusan node ini mengikuti aturan pertama |
 |
| node 9 menggantikan posisi 8, dan node 9 berubah jadi merah. setelah dihapus node 8, terjadi ketidakseimbangan di node 9, pada subtree kiri 9, ada 2 anak, sedangkan subtree kanannya tidak ada alias 0, ingat aturan AVL/RBT, bahwa ssubtree kiri dan kanan hanya boleh seilsih maksimal 1 node, karena di kasus ini selisih 2, maka kita harus menyeimbangkannya kembali dengan menggunakan double rotation (left-right) |
 |
| double rotation : step 1
rotasi 5 dan 6 dengan rotasi kiri, karena 5 ke 6 kanan, rotasi kebalikannya |
 |
| double rotation : step 2
rotasi 6 dan 9, karena 9 ke 6 kiri, maka rotasi kanan
meskipun node 9 berubah warna pada step-step sebelumnya, akan tetapi warna node tidak berubah pada warna asal node sebelum node 8 dihapus |
contoh 3 :
 |
| kita akan menghapus node 15. |
 |
| node 15 digantikan oleh anak kanan terkecilnya yaitu 20
pada penghapusan node kali ini mengikuti aturan ke 2, karena node yg dihapus berwarna hitam dan anak yang menggantikannya berwarna merah. oleh karena itu, 20 berubah warna menjadi hitam |
contoh 4 :
 |
| kita akan menghapus node 12 yang berwarna hitam dan akan digantikan node 13 |
 |
| node 12 digantikan node 13 yang juga berwarna hitam maka ikuti aturan ke 3
pada gambar sebelumnya, kita dapat menentukan N = 13, P = 14, S = 20, Sl = 17 dan Sr = tidak ada
karena sibling hitam, dan anaknya ada yang merah maka mengikuti aturan 3c |
 |
| rotasi dilakukan pada node 14 yang tidak seimbang.
kita melakukan single rotasi karena dari 14 ke 17 kanan dan 17 ke 20 kanan (right-right) |
 |
| node 17 berubah warna menjadi merah dan node 14, 20 berubah menjadi warna hitam |
2-3 Tree
2-3 tree adalah sebuah struktur data dimana setiap internal nodenya (non leaf) adalah 2-node atau 3-node dan semua leafnya berada pada level yang sama
- 2-node adalah suatu node yang memiliki 1 data dan 2 anak
- 3-node adalah suatu node yang memiliki 2 data dan 3 anak
data-data yang disimpan setiap node pada 2-3 tree harus sudah berurutan
contoh 2-3 Tree :
2-3 Tree Operations : Search
operasi searching pada 2-3 tree sama seperti pada BST, sehingga hanya perlu membandingkan data yang dicari dengan data yang ada pada node. Misal K adalah node yang dicari dan N adalah node yang akan dibandingkan dengan tree, maka jika K lebih kecil dari N, operasi searching berlanjut ke subtree kiri N namun jika K lebih besar dari N, maka operasi searching berlanjut ke subtree kanan N. Ini terjadi terus-menerus sampai K = N, atau K ditemukan.
2-3 Tree Operations : Insertion
aturan insertion :
- anggap node yang di insert adalah key
- key akan ditempatkan pada leaf. a) jika leaf adalah 2-node, maka key dimasukan kedalam leaf sehingga leaf tersebut menjadi 3-node. b) jika leaf adalah 3-node, maka ambil nilai tengah dari A, B, dan key (A adalah data-1 pada leaf, dan B adalah data-2 pada leaf) dan push nilai tengah tersebut pada parentnya
- jika pada saat aturan kedua parentnya bukanlah 2-node, melainkan 3-node, tentukan kembali nilai tengah lalu push kembali ke parentnya
- jika pada saat aturan ke 2 dan 3 tidak bisa dilakukan karena parent sampai ke rootnya adalah 3-node, maka tentukan kembali nilai tengah, kemudian nilai tengah tersebut akan dibuat root baru.
contoh 1 :
 |
| insert node 45, kita akan mencari posisi yang tepat untuk 45, pada leaf di sebelah kanan 30. karena leaf tersebut merupakan 2-node, maka sesuai aturan ke 2a, 45 langsung diletakan pada leaf sehingga leaf membentuk 3-node |
contoh 2 :
 |
| insert node 75, posisi yang tepat adalah di leaf pada sebelah kanan 70, namun leaf tersebut adalah 3-node, maka kita ikuti aturan 2b. Nilai tengah dari 75, 80 dan 90 adalah 80, karena 80>75 dan 80<90.
kita push 80 pada parentnya yaitu 2-node yang datanya 70.
karena parentnya adalah 2-node maka kita dapat langsung memasukan datanya |
 |
| karena saat ini parent 70 berubah dari 2-node menjadi 3-node, maka ia harus memiliki 3 anak, sehingga 75 dan 90 kita pisahkan menjadi 2 anak. Jadilah demikian |
contoh 3 :
 |
| insert 24, posisi yang tepat adalah di antara node 20 dan 30, karena 24>20 dan 24<30. namun leaf pada posisi tengah dari 20 dan 30 adalah 3-node, maka kita tentukan nilai tengah, yaitu 24, lalu push 24 ke parentnya. |
 |
| Akan tetapi parentnya juga merupakan 3-node (dengan data 20 dan 30), maka kita ikuti aturan ke-3, sehingga kita tentukan lagi nilai tengahnya, yaitu 24, lalu push 24 ke parentnya (parent dari parent) lagi. Parent tersebut merupakan 2-node dengan data 50, sehingga kita dapat langsung memasukan nilainya pada parent. |
 |
| karena saat ini parentnya telah berubah menjadi 3-node, maka harus memiliki 3 anak, maka kita pisahkan 3-node sebelumnya menjadi 2 bagian. seperti pada gambar diatas. |
contoh 4 :
 |
| insert 95, posisi yang tepat adalah leaf pada sebelah kanan 80, namun leaf tersebut adalah 3-node, sehingga kita harus menentukan nilai tengahnya, yaitu 95. lalu push pada parentnya |
 |
| ternyata parentnya adalah 3-node lagi, maka kita tentukan nilai tengahnya lagi, yaitu 80, kemudian push pada parent dari parent nya kembali |
 |
| parentnya merupakan 3-node, dan parentnya adalah root, sehingga tidak mungkin kita push ke parent dari parentnya lagi, karena root tidak memiliki parent, maka kita lakukan aturan ke-4. kita tentukan nilai tengahnya, yaitu 50, dan 50 tersebut kita jadikan root baru (2-node) |
 |
| 50 menjadi root 2-node, karena root berbentuk 2-node, maka harus memiliki 2 anak, maka kita pisahkan node-node yang ada dibawahnya menjadi demikian. |
2-3 Tree Operations : Deletion
aturan deletion :
- misal node yang dihapus adalah key
- delete sama seperti BST, yaitu digantikan oleh leafnya
- jika leaf 3-node, maka ambil salah satu data untuk menggantikan key, seperti BST, terbesar dari subtree kiri atau terkecil dari subtree kanan
- jika leaf 2-node, maka :
- jika parent dari leaf adalah 3-node, maka ambil satu data dari parent. kemudian kita perhatikan kembali siblingnya. a) jika sibling 3-node, maka ambil satu data kemudian push pada parent, agar parent kembali menjadi 3-node, b) jika sibling 2-node, maka biarkan parent menjadi 2-node, dan satukan node tersebut dengan siblingnya
- jika parent dari leaf adalah 2-node, kita perhatikan siblingnya. a) jika sibling 3-node, ambil satu data dari parent dan push satu nilai dari sibling ke parent. b) jika sibling 2-node, maka satukan sibling dengan parent.
contoh 1 :
 |
| kita akan menghapus 23, karena 23 adalah leaf, dan merupakan 3-node, maka hapus saja langsung. dan biarkan leaf berubah dari 3-node menjadi 2-node |
 |
| menjadi demikian |
contoh 2 :
 |
| delete 50, maka digantikan oleh anak kiri terbesar yaitu 40, karena 40 merupakan leaf 2 node, maka kita mengikuti aturan ke-4 yang pertama (karena parent dari 40 adalah 3-node). |
 |
| 40 menggantikan 50, lalu ambil salah satu dari parent, yaitu 30 (karena node yang kosong disebelah kanan, maka kita ambil yang terbesar dari 20 dan 30). karena siblingnya merupakan 2-node, maka kita ikuti aturan ke-4 pertama yang b |
 |
| parent dibiarkan menjadi 2 node, dan kita satukan 30 dengan siblingnya yaitu disebelah kanan 25, karena tidak mungkin di kiri 15,dan diantara 15 dan 25 karena 30 lebih besar dari keduanya, sehingga diletakan paling kanan. Jadilah demiikian
|
STRUKTUR DATA - B Tree and Heap & Deap
B-Tree
Pada B-Tree dikenal istilah order. Order menentukan jumlah maksimum/minimum anak yang dimiliki oleh setiap node, sehingga order merupakan hal yang cukup penting dalam B-Tree. 2-3 Tree pada postingan sebelumnya yaitu Balanced Binary Search Tree (AVL and RBT) and 2-3 Tree merupakan salah satu B-Tree berorder 3. Itu sebabnya setiap nodenya memiliki batasan anak, dengan minimal 2 anak dan maksimal 3 anak.
Aturan pada B-Tree : m = order
- Setiap node (kecuali leaf) memiliki anak paling banyak sejumlah m anak
- Setiap node (kecuali root) memiliki anak paling sedikit m/2 anak
- Root memiliki anak minimal 2, selama root bukan leaf
- Jika node non leaf memiliki k anak, maka jumlah data yang tersimpan dalam node k-1
- Data yang tersimpan pada node harus terurut secara inorder
- Semua leaf berada pada level yang sama, level terbawah
Berikut contoh B-Tree :
 |
| B-Tree order 4 |
 |
| B-Tree order 6 |
Operasi : Searching
Searching pada B-Tree mirip seperti 2-3 Tree. Pertama-tama kita bandingkan dengan rootnya terlebih dahulu kemudian cek apakah sama dengan rootnya atau lebih kecil atau lebih besar atau bahkan diantara rootnya (jika root memiliki lebih dari 1 data).
berikut ini adalah codingannya dalam C :
Operasi : Insertion
Aturan Insertion :
- Anggap data yang mau di insert adalah key
- Posisikan key pada node yang sesuai, seperti pada BST dan 2-3 Tree, anggap node tersebut A
- Jika A adalah node dengan jumlah data kurang dari m-1, maka langsung masukan saja
- Jika A adalah node dengan jumlah data m-1, maka masukan nilai tengah kemudian masukan ke parentnya. Kemudian anggaplah parent tersebut A. Kemudian periksa kembali sesuai aturan point ke 3 dan 4.
gambar dibawah ini adalah operasi insertion pada b-tree berorder 5
Operasi : Deletion
Aturan Deletion :
- Anggap node yang mau di delete adalah key
- Delete dilakukan pada leaf. Meskipun pada saat menghapus node parent, kita tetap menganggapnya menghapus leaf, karena ketika parent dihapus lalu digantikan oleh anak terbesar subtree kiri atau anak terkecil subtree kanan sama saja kita seolah-olah menghapus anak yang menggantikannya. dimana anak tersebut selalu berada pada posisi leaf. maka leaf tersebut dianggap P.
- Jika ukuran P > m/2 maka langsung delete saja data yang ingin dihapus
- Jika ukuran P = m/2 maka : perhatikan siblingnya (anggap sibling adalah Q)
- Q > m/2, maka rotasi pada P
- Q = m/2, satukan P dan Q
contoh :
delete pada b-tree order 5
Heap and Deap
heap
Heap adalah complete binary tree yang berbasis struktur data dan memenuhi aturan heap. Tree pada heap and deap tidak memenuhi aturan BST yang harus terurut secara inorder, yang penting tree tersebut mengikuti aturan heap.
Ada 2 jenis heap :
- Min Heap : node paling kecil adalah root dan semakin kebawah levelnya semakin besar
- Max Heap : node paling besar adalah root dan semakin kebawah levelnya semakin kecil
- Min-Max Heap : min-heap dan max-heap levelnya saling bergantian pada tree
contoh :
 |
| kiri : min heap ------- kanan : max heap |
Heap biasanya diimplementasi kan pada array dan indexnya dimulai dari 1, bukan 0.
cara mengetahui lokasi index parent dan child :
- Parent(x) = x / 2 dengan x = index anak
- Left-child(x) = 2 * x dengan x = index parent
- Right-child(x) = 2 * x + 1 dengan x = index parent
Min Heap
Operasi : Find Min
Pada min-heap, untuk menemukan node terkecil sangatlah mudah, karena root dari min heap adalah node dengan nilai terkecil.
Operasi : Insertion
- Insert node baru (key) pada index selanjutnya (setelah index terakhir)
- lakukan upheap, yaitu compare key dengan parentya, jika node parent > key, maka swap. Jika tidak maka biarkan saja
- lakukan point ke-2 berulang kali jika setelah diswap masih parent > key. namun stop jika key sudah berada pada posisi root.
contoh :
insert 5
insert 20
Operasi : Deletion
aturan delete :
- operasi delete hanya terjadi pada rootnya saja.
- gantikan elemen yang didelete dengan node yang berada pada index terakhir
- lakukan downheap, yaitu compare dengan salah satu childnya yang terkecil. jika node tersebut > child terkecil, maka swap
- lakukan point ke-3 jika setelah diswap node tersebut masih memiliki anak. Namun stop jika node sudah dalam posisi leaf atau node tersebut < child terkecilnya
contoh :
delete node 7
 |
| node 7 dihapus kemudian diganti oleh node index terakhir, yaitu 28
kemudian 28 di compare dengan anak terkecilnya 10 |
 |
| 28>10, maka swap
kemudian 28 dicompare lagi dengan anak terkecilnya, 12.
28>12, swap kembali. karena 28 sekarang pada posisi leaf. maka updown dihentikan |
Max Heap
Max heap adalah kebalikan dari min heap.
Operasi : Find Max
Pada max-heap, untuk menemukan node terbesar sangatlah mudah, karena root dari max heap adalah node dengan nilai terbesar.
Operasi : Insertion
- Insert node baru (key) pada index selanjutnya (setelah index terakhir)
- lakukan uphead, yaitu compare key dengan parentnya, jika node parent < key maka swap. Jika tidak maka biarkan saja
- lakukan point ke-2 berulang kali jika setelah diswap masih parent < key. namun stop jika key sudah berada pada posisi root.
contoh :
insert 15
 |
| pada saat di insert 15, kemudian dicompare dengan parentnya ternyata 15>7, maka swap
kemudian setelah diswap dicompare lagi dengan parentnya ternyata 15>14, maka diswap lagi |
Operasi : Deletion
aturan delete :
- operasi delete hanya terjadi pada rootnya saja.
- gantikan elemen yang didelete dengan node yang berada pada index terakhir
- lakukan downheap, yaitu compare dengan salah satu childnya yang terbesar. jika node tersebut < child terbesar, maka swap
- lakukan point ke-3 jika setelah diswap node tersebut masih memiliki anak. Namun stop jika node sudah dalam posisi leaf atau node tersebut > child terbesarnya
contoh :
delete 20
 |
| 20 akan digantikan oleh 15, karena 15 berada pada index terakhir |
 |
| 15 dibandingkan dengan parentnya. ternyata 15<34, maka tidak diswap dan operasi insertion selesai |
Min-Max Heap
Min-Max Heap adalah penggabungan dari min-heap dan max-heap. dimana pada tree ini kita dapat mendapatkan 1 angka terkecil dan 2 angka terbesar. Namun sayangnya, angka terbesar tersebut salah satunya memang terbesar tetapi satunya lagi belum pasti nilai terbesar keduanya.
berikut contohnya :
level pertama pada min-max heap adalah min level dan bawahnya max level.
nilai terkecil pada tree terletak pada rootnya sedangkan 2 nilai terbesarnya adalah anak dari rootnya.
Operasi : Insertion
- Insert node baru (key) pada index selanjutnya (setelah index terakhir)
- jika key terletak pada level min : bandingkan dengan parentnya
- Jika parent < key maka swap dan upheapmax dari parentnya (dibandingkan dengan grandparentnya dari posisi key setelah swap)
- Jika parent > key, upheapmin dari posisi key (dibandingkan dengan grandparentnya dari posisi key).
- jika key terletak pada level max :
- Jika parent > key maka swap dan upheapmin dari parentnya (dibandingkan dengan grandparentnya dari posisi keysetelah swap)
- jika parent < key, upheapmax dari posisi key(dibandingkan dengan grandparentnya dari posisi key).
Operasi : Deletion
ada 2 jenis delete, yaitu delete min, dan delete max
- Delete Min, menghapus node terkecil, yaitu root
- Delete Max, menghapus node terbesar, yaitu salah satu dari anak root
konsep deletenya sama :
- node yang dihapus digantikan oleh node index terakhir
- lakukan downheapmin jika delete min, atau downheapmax jika delete max
Deap
Deap adalah gabungan dari min heap dan max heap, namun berbeda dengan min-max heap, karena pada deap, rootnya tidak ada, atau kosong/NULL dan subtree kirinya adalah min heap dan subtree kanannya adalah max heap.
contoh :
pada deap, dikenal istilah partner, yaitu pasangan node
pada gambar diatas, pasangannya dapat dilihat dari warnanya
5 -->45
10-->25
8 -->40
15-->20
19-->22
9 -->40
30-->40
mengapa partner 9 dan 30 adalah 40?? karena jika suatu node tidak memiliki pasangan pada subtree kanan atau sebaliknya, maka node tersebut dipasangkan dengan parent dari node yang seharusnya. pada node 9 seharusnya dipasangkan dengan node dengan imdex 14, tapi karena node index 14 tidak ada/NULL maka dipasangkan dengan 40 yang merupakan induk dari node index 14.
Operasi : Insertion
- masukkan node baru pada index selanjutnya (setelah index terakhir)
- jika key terletak pada min heap
- bandingkan dengan max partner
- jika max partnernya < key, swap
- lakukan min upheap, yaitu up heap di min subtree
- jika key terletak pada max heap
- bandingkan dengan min partner
- jika min partnernya > key, swap
- lakukan max upheap, yaitu up heap di max subtree
contoh :
insert 50



Operasi : Deletion
- ada 2 jenis delete, delete min dan delete max
- jika delete min
- gantikan node yang dihapus dengan node index terakhir
- lakukan downheap min
- compare dengan partnernya, jika partner < node tersebut, swap
- jika delete max
- gantikan node yang dihapus dengan node index terakhir
- lakukan downheap max
- compare dengan partnernya, jika partner > node tersebut, swap
contoh :
delete 5
STRUKTUR DATA - B Tree and Heap & Deap
B-Tree
Pada B-Tree dikenal istilah order. Order menentukan jumlah maksimum/minimum anak yang dimiliki oleh setiap node, sehingga order merupakan hal yang cukup penting dalam B-Tree. 2-3 Tree pada postingan sebelumnya yaitu Balanced Binary Search Tree (AVL and RBT) and 2-3 Tree merupakan salah satu B-Tree berorder 3. Itu sebabnya setiap nodenya memiliki batasan anak, dengan minimal 2 anak dan maksimal 3 anak.
Aturan pada B-Tree : m = order
- Setiap node (kecuali leaf) memiliki anak paling banyak sejumlah m anak
- Setiap node (kecuali root) memiliki anak paling sedikit m/2 anak
- Root memiliki anak minimal 2, selama root bukan leaf
- Jika node non leaf memiliki k anak, maka jumlah data yang tersimpan dalam node k-1
- Data yang tersimpan pada node harus terurut secara inorder
- Semua leaf berada pada level yang sama, level terbawah
Berikut contoh B-Tree :
|
| B-Tree order 4 |
|
| B-Tree order 6 |
Operasi : Searching
Searching pada B-Tree mirip seperti 2-3 Tree. Pertama-tama kita bandingkan dengan rootnya terlebih dahulu kemudian cek apakah sama dengan rootnya atau lebih kecil atau lebih besar atau bahkan diantara rootnya (jika root memiliki lebih dari 1 data).
berikut ini adalah codingannya dalam C :
Operasi : Insertion
Aturan Insertion :
- Anggap data yang mau di insert adalah key
- Posisikan key pada node yang sesuai, seperti pada BST dan 2-3 Tree, anggap node tersebut A
- Jika A adalah node dengan jumlah data kurang dari m-1, maka langsung masukan saja
- Jika A adalah node dengan jumlah data m-1, maka masukan nilai tengah kemudian masukan ke parentnya. Kemudian anggaplah parent tersebut A. Kemudian periksa kembali sesuai aturan point ke 3 dan 4.
gambar dibawah ini adalah operasi insertion pada b-tree berorder 5
Operasi : Deletion
Aturan Deletion :
- Anggap node yang mau di delete adalah key
- Delete dilakukan pada leaf. Meskipun pada saat menghapus node parent, kita tetap menganggapnya menghapus leaf, karena ketika parent dihapus lalu digantikan oleh anak terbesar subtree kiri atau anak terkecil subtree kanan sama saja kita seolah-olah menghapus anak yang menggantikannya. dimana anak tersebut selalu berada pada posisi leaf. maka leaf tersebut dianggap P.
- Jika ukuran P > m/2 maka langsung delete saja data yang ingin dihapus
- Jika ukuran P = m/2 maka : perhatikan siblingnya (anggap sibling adalah Q)
- Q > m/2, maka rotasi pada P
- Q = m/2, satukan P dan Q
contoh :
delete pada b-tree order 5
Heap and Deap
heap
Heap adalah complete binary tree yang berbasis struktur data dan memenuhi aturan heap. Tree pada heap and deap tidak memenuhi aturan BST yang harus terurut secara inorder, yang penting tree tersebut mengikuti aturan heap.
Ada 2 jenis heap :
- Min Heap : node paling kecil adalah root dan semakin kebawah levelnya semakin besar
- Max Heap : node paling besar adalah root dan semakin kebawah levelnya semakin kecil
- Min-Max Heap : min-heap dan max-heap levelnya saling bergantian pada tree
contoh :
|
| kiri : min heap ------- kanan : max heap |
Heap biasanya diimplementasi kan pada array dan indexnya dimulai dari 1, bukan 0.
cara mengetahui lokasi index parent dan child :
- Parent(x) = x / 2 dengan x = index anak
- Left-child(x) = 2 * x dengan x = index parent
- Right-child(x) = 2 * x + 1 dengan x = index parent
Min Heap
Operasi : Find Min
Pada min-heap, untuk menemukan node terkecil sangatlah mudah, karena root dari min heap adalah node dengan nilai terkecil.
Operasi : Insertion
- Insert node baru (key) pada index selanjutnya (setelah index terakhir)
- lakukan upheap, yaitu compare key dengan parentya, jika node parent > key, maka swap. Jika tidak maka biarkan saja
- lakukan point ke-2 berulang kali jika setelah diswap masih parent > key. namun stop jika key sudah berada pada posisi root.
contoh :
insert 5
insert 20
Operasi : Deletion
aturan delete :
- operasi delete hanya terjadi pada rootnya saja.
- gantikan elemen yang didelete dengan node yang berada pada index terakhir
- lakukan downheap, yaitu compare dengan salah satu childnya yang terkecil. jika node tersebut > child terkecil, maka swap
- lakukan point ke-3 jika setelah diswap node tersebut masih memiliki anak. Namun stop jika node sudah dalam posisi leaf atau node tersebut < child terkecilnya
contoh :
delete node 7
|
| node 7 dihapus kemudian diganti oleh node index terakhir, yaitu 28
kemudian 28 di compare dengan anak terkecilnya 10 |
|
| 28>10, maka swap
kemudian 28 dicompare lagi dengan anak terkecilnya, 12.
28>12, swap kembali. karena 28 sekarang pada posisi leaf. maka updown dihentikan |
Max Heap
Max heap adalah kebalikan dari min heap.
Operasi : Find Max
Pada max-heap, untuk menemukan node terbesar sangatlah mudah, karena root dari max heap adalah node dengan nilai terbesar.
Operasi : Insertion
- Insert node baru (key) pada index selanjutnya (setelah index terakhir)
- lakukan uphead, yaitu compare key dengan parentnya, jika node parent < key maka swap. Jika tidak maka biarkan saja
- lakukan point ke-2 berulang kali jika setelah diswap masih parent < key. namun stop jika key sudah berada pada posisi root.
contoh :
insert 15
|
| pada saat di insert 15, kemudian dicompare dengan parentnya ternyata 15>7, maka swap
kemudian setelah diswap dicompare lagi dengan parentnya ternyata 15>14, maka diswap lagi |
Operasi : Deletion
aturan delete :
- operasi delete hanya terjadi pada rootnya saja.
- gantikan elemen yang didelete dengan node yang berada pada index terakhir
- lakukan downheap, yaitu compare dengan salah satu childnya yang terbesar. jika node tersebut < child terbesar, maka swap
- lakukan point ke-3 jika setelah diswap node tersebut masih memiliki anak. Namun stop jika node sudah dalam posisi leaf atau node tersebut > child terbesarnya
contoh :
delete 20
|
| 20 akan digantikan oleh 15, karena 15 berada pada index terakhir |
|
| 15 dibandingkan dengan parentnya. ternyata 15<34, maka tidak diswap dan operasi insertion selesai |
Min-Max Heap
Min-Max Heap adalah penggabungan dari min-heap dan max-heap. dimana pada tree ini kita dapat mendapatkan 1 angka terkecil dan 2 angka terbesar. Namun sayangnya, angka terbesar tersebut salah satunya memang terbesar tetapi satunya lagi belum pasti nilai terbesar keduanya.
berikut contohnya :
level pertama pada min-max heap adalah min level dan bawahnya max level.
nilai terkecil pada tree terletak pada rootnya sedangkan 2 nilai terbesarnya adalah anak dari rootnya.
Operasi : Insertion
- Insert node baru (key) pada index selanjutnya (setelah index terakhir)
- jika key terletak pada level min : bandingkan dengan parentnya
- Jika parent < key maka swap dan upheapmax dari parentnya (dibandingkan dengan grandparentnya dari posisi key setelah swap)
- Jika parent > key, upheapmin dari posisi key (dibandingkan dengan grandparentnya dari posisi key).
- jika key terletak pada level max :
- Jika parent > key maka swap dan upheapmin dari parentnya (dibandingkan dengan grandparentnya dari posisi keysetelah swap)
- jika parent < key, upheapmax dari posisi key(dibandingkan dengan grandparentnya dari posisi key).
Operasi : Deletion
ada 2 jenis delete, yaitu delete min, dan delete max
- Delete Min, menghapus node terkecil, yaitu root
- Delete Max, menghapus node terbesar, yaitu salah satu dari anak root
konsep deletenya sama :
- node yang dihapus digantikan oleh node index terakhir
- lakukan downheapmin jika delete min, atau downheapmax jika delete max
Deap
Deap adalah gabungan dari min heap dan max heap, namun berbeda dengan min-max heap, karena pada deap, rootnya tidak ada, atau kosong/NULL dan subtree kirinya adalah min heap dan subtree kanannya adalah max heap.
contoh :
pada deap, dikenal istilah partner, yaitu pasangan node
pada gambar diatas, pasangannya dapat dilihat dari warnanya
5 -->45
10-->25
8 -->40
15-->20
19-->22
9 -->40
30-->40
mengapa partner 9 dan 30 adalah 40?? karena jika suatu node tidak memiliki pasangan pada subtree kanan atau sebaliknya, maka node tersebut dipasangkan dengan parent dari node yang seharusnya. pada node 9 seharusnya dipasangkan dengan node dengan imdex 14, tapi karena node index 14 tidak ada/NULL maka dipasangkan dengan 40 yang merupakan induk dari node index 14.
Operasi : Insertion
- masukkan node baru pada index selanjutnya (setelah index terakhir)
- jika key terletak pada min heap
- bandingkan dengan max partner
- jika max partnernya < key, swap
- lakukan min upheap, yaitu up heap di min subtree
- jika key terletak pada max heap
- bandingkan dengan min partner
- jika min partnernya > key, swap
- lakukan max upheap, yaitu up heap di max subtree
contoh :
insert 50
Operasi : Deletion
- ada 2 jenis delete, delete min dan delete max
- jika delete min
- gantikan node yang dihapus dengan node index terakhir
- lakukan downheap min
- compare dengan partnernya, jika partner < node tersebut, swap
- jika delete max
- gantikan node yang dihapus dengan node index terakhir
- lakukan downheap max
- compare dengan partnernya, jika partner > node tersebut, swap
contoh :
delete 5